redis的应用场景
不同数据类型的内存管理介绍
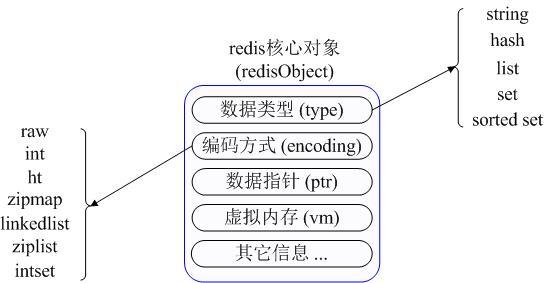
如上图所示,首先Redis内部使用一个redisObject对象来表示所有的key和value,redisObject最主要的信息如上图所示:type 代表一个value对象具体是何种数据类型,encoding是不同数据类型在redis内部的存储方式,比如:type=string代表value存储的是一个普通字符串,那么对应的encoding可以是raw或者是int,如果是int则代表实际redis内部是按数值型类存储和表示这个字符串的,当然前提是这个字符串本身可以用数值表示,比如:"123" "456"这样的字符串。
我们可以发现Redis使用redisObject来表示所有的key/value数据是比较浪费内存的,当然这些内存管理成本的付出主要也是为了给Redis不同数据类型提供一个统一的管理接口。
不同的数据类型对应的使用场景
string
- 防重复提交(分布式锁)
规定某个key值在某段时间内只能出现一次
# 有一致性问题
function redisLock($syncKey,$expire=1000){
if (!$this->redis->setnx ( $syncKey, 1 )) {
return false;
}
$this->redis->pexpire($syncKey, $expire);
return true;
}
# 2.6版本以后
/**
* redis排重锁
* @param $key
* @param $expires
* @param int $value
* @return mixed
*/
public function redisLock($key, $expires, $value = 1)
{
//在key不存在时,添加key并$expires秒过期
return $this->redis->set($key, $value, ['nx', 'ex' => $expires]);
}
- 原子计数器
Redis的命令都是原子性的,你可以轻松地利用INCR,DECR命令来构建计数器系统。
- 普通缓存json数据
Hash
- 存储、读取、修改用户属性
在 Memcached 中,我们经常将一些结构化的信息打包成 hashmap,在客户端序列化后存储为一个字符串的值(一般是 JSON 格式),比如用户的昵称、年龄、性别、积分等。这时候在需要修改其中某一项时,通常需要将字符串(JSON)取出来,然后进行反序列化,修改某一项的值,再序列化成字符串(JSON)存储回去。简单修改一个属性就干这么多事情,消耗必定是很大的,也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分)。而 Redis 的 Hash 结构可以使你像在数据库中 Update一个属性一样只修改某一项属性值。
List
- 构建队列系统
使用rpush/lpush操作入队列,使用lpop 和 rpop来出队列。如果队列空了,客户端就会陷入 pop 的死循环,不停地 pop。通常我们使用 sleep 来解决这个问题,让线程睡一会,睡个 1s 钟就可以了。但是有个小问题,那就是睡眠会导致消息的延迟增大。如果只有 1 个消费者,那么这个延迟就是 1s。
用blpop/brpop替代前面的lpop/rpop,阻塞读在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。消息的延迟几乎为零。但如果线程一直阻塞在哪里,Redis 的客户端连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用。这个时候blpop/brpop会抛出异常来。所以编写客户端消费者的时候要小心,注意捕获异常,还要重试。
- 实现冷热数据交换,并取最新的N条热数据
比如处理某篇文章的评论时,我们可以先把最新的评论通过Hash和List的方式来存储;Hash中以ID为键,然后把这个ID存入List中,写定时脚本把冷数据存入数据库。
假设后五千条评论为冷数据,我们将最新的5000条评论从List中取出来:
- 使用LPUSH latest.comments<ID>命令,向list集合中插入数据
- 定时脚本判断(或者在插入的时候判断一下)是否超过五千,如果超过五千,就把其数据保存数据库并清掉
- 如果有不同的筛选维度,比如某个分类的最新N条,那么你可以再建一个按此分类的List,只存ID的话,Redis是非常高效的。
function get_latest_comments(start,num_items):
id_list = redis.lrange("latest.comments",start,start+num_items-1)
IF id_list.length < num_items
id_list = SQL_DB("SELECT ... ORDER BY time LIMIT ...")
END
RETURN id_list
END
zset
排行榜应用
与取最新数据的不同之处在于,前面操作以时间为权重(list就可以满足),这个是以某个条件为权重,比如按顶的次数排序,这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value,每次只需要执行一条ZADD命令即可。
zset 还可以用来存储学生的成绩,value 值是学生的 ID,score 是他的考试成绩。我们可以对成绩按分数进行排序就可以得到他的名次。
粉丝列表
zset 可以用来存粉丝列表,value 值是粉丝的用户 ID,score 是关注时间。我们可以对粉丝列表按关注时间进行排序。
构建优先级队列系统
延时队列
我们将消息序列化成一个字符串作为 zset 的value,这个消息的到期处理时间作为score,**然后用多个线程轮询 zset 获取到期的任务进行处理,多个线程是为了保障可用性,万一挂了一个线程还有其它线程可以继续处理。**因为有多个线程,所以需要考虑并发争抢任务,确保任务不能被多次执行。
def delay(msg):
msg.id = str(uuid.uuid4()) # 保证 value 值唯一
value = json.dumps(msg)
retry_ts = time.time() + 5 # 5 秒后重试
redis.zadd("delay-queue", retry_ts, value)
def loop():
while True:
# 最多取 1 条
values = redis.zrangebyscore("delay-queue", 0, time.time(), start=0, num=1)
if not values:
time.sleep(1) # 延时队列空的,休息 1s
continue
value = values[0] # 拿第一条,也只有一条
success = redis.zrem("delay-queue", value) # 从消息队列中移除该消息
if success: # 因为有多进程并发的可能,最终只会有一个进程可以抢到消息
msg = json.loads(value)
handle_msg(msg)
set
数据排重
关于 redis的无序集合有三个特点: 无序性, 确定性(描述准确) , 唯一性。只需要不断地将数据往set中扔,得到的数据肯定是uniq的。
集合应用
Redis 非常人性化的为集合提供了求交集、并集、差集等操作,那么就可以非常方便的实现如共同关注、共同喜好、二度好友等功能,对上面的所有集合操作,你还可以使用不同的命令选择将结果返回给客户端还是存集到一个新的集合中。
- 共同好友、二度好友
- 利用唯一性,可以统计访问网站的所有独立 IP
- 好友推荐的时候,根据 tag 求交集,大于某个 threshold 就可以推荐
Pub/Sub
Pub/Sub构建实时消息系统 (一般不用)
Geo
附近的XXX
内容来源于网络,如有侵权,请联系作者删除!
