Mybatis知识点整理
1、Mybatis概述
**1.1 JDBC编程

1.2.说说你对Mybatis的了解
1.Mybatis 基于java的持久层框架,它的内部封装了JDBC,让开发人员只需要关注SQL语句本身,不需要花费精力在驱动的加载、连接的创建、Statement的创建等复杂的过程。
2.Mybatis 通过 XML 或注解的方式将要执行的各种的 statement 配置起来,并通过 java 对象和 statement 中的 sql 的动态参数进行映射生成最终执行的SQL 语句,最后 由mybatis框架执行SQL,并将结果直接映射为java对象 。
3.采用了 ORM思想 解决了实体类和数据库表映射的问题。对 JDBC进行了封装 ,屏蔽了 JDBCAPI 底层的访问细节,避免我们与 jdbc 的 api 打交道,就能完成对数据的持久化操作。

1.3 Mybatis****解决的问题
1、数据库连接的创建、释放连接的频繁操作造成资源的浪费从而影响系统的性能。
2、SQL语句编写在代码中,硬编码造成代码不容易维护,实际应用中SQL语句变化的可能性比较大,一旦变动就需要改变java类。
3、使用preparedStatement的时候传递参数使用占位符,也存在硬编码,因为SQL语句变化,必须修改源码。
4、对结果集的解析中也存在硬编码。
2**、Mybatis入门案例**
2.1****创建数据库和表
CREATE TABLE `team` (
`teamId` int NOT NULL AUTO_INCREMENT COMMENT '球队ID',
`teamName` varchar(50) DEFAULT NULL COMMENT '球队名称',
`location` varchar(50) DEFAULT NULL COMMENT '球队位置',
`createTime` date DEFAULT NULL COMMENT '球队建立时间',
PRIMARY KEY (`teamId`)
) ENGINE=InnoDB AUTO_INCREMENT=1003 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;2.2创建maven项目,添加Mybatis的jar****依赖
创建个java的maven项目

2.3编写Mybatis****的配置文件
一般情况下:配置文件的名称可以自定义,使用mybatis.xml。配置文件放置在java/resources中。
头文件去官网中复制粘贴。提供一个中文的网站。Mybatis网址
配置文件中配置mybatis的环境(数据源、事务类型)

2.4****编写实体类
实体类中的属性必须与表中的列名保持一致,默认构造+set+get(不能少)


2.5编写ORM****映射文件
我们是针对实体类Team.java和表Team进行ORM映射.
Mybatis 框架中, ORM 映射是针对 SQL 语句进行, Mybatis 框架将 SQL 语句抽取到了 XML 中。所以我们需要针对每个实体类编写 XML 映射文件。
2.5.1 XML****映射文件必须与实体类在同一个包下面
2.5.2 XML****映射文件名称必须是实体类名称一致
头文件在网站复制即可。Mybatis网址
注意namespace、id、resultType分别表示什么。

2.6将映射文件注册到mybatis****的配置文件中

2.7****配置映射文件的扫描位置
pom.xml 文件配置映射文件的扫描路径
因为src/main/java目录下的配置完文件(.xml/.properties)是无法读取到,需要在pom.xml中去指定配置文件的扫描路径

2.8使用Mybatis****框架的核心接口测试


2.9. 配置日志文件
2.9.1.添加jar****依赖

2.9.2.添加日志配置文件
在 resource 下添加 log4j.properties 配置文件


# Global logging configuration info warning error
log4j.rootLogger=DEBUG,stdout
# Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n2.9.3.在mybatis配置文件中添加日志的配置

**2.10.**入门案例的增删改查
2.10.0.注意:手动提交事务
增删改操作,必须手动提交事务,否则不生效
因为上面在mybatis配置中,指定了JDBC方式(Connection)管理事务,默认自动提交是false,
解决1.每执行一次增删改sql,我们手动提交sqlSession.commit()
解决2.在获取sqlSession会话时,开启自动事务,参数true,即factory.openSession(true)
这只是在dao层操作事务,不推荐,将来事务都是在service层通过声明式事务管理
实体类

2.10.0.在测试类中使用测试注解@Before @After减少重复代码

2.10.1根据ID****查询单个对象
parameterType:参数类型,sql中占位符类型,该属性基本类型时可省略,实体类型则不可省略
resultType:返回类型,执行这条sql后返回什么类型的结果,基本类型可省略不写,若集合则其元素类型-->
报错原因:实体类没有加默认构造方法

Team.xml的映射文件中添加:

测试类中添加如下内容:

2.10.2****增删改
Team.xml 的映射文件中添加:

测试类中添加如下方法:

2.10.3.查询所有
映射文件添加
测试类添加
3**、Mybatis对象分析**
3.1 Resources
Resources 类,顾名思义就是资源,用于读取资源文件。其有很多方法通过加载并解析资源文件,返回不同类型的 IO 流对象。
3.2 SqlSessionFactoryBuilder
SqlSessionFactory 的 创 建 , 需 要 使 用 SqlSessionFactoryBuilder 对 象 的 build() 方 法 。 事实上使用 SqlSessionFactoryBuilder 的原因是将SqlSessionFactory 这个复杂对象的创建交由 Builder 来执行,也就是使用了 建造者设计模式 。
建造者模式 : 又称生成器模式 , 是一种 对象的创建模式 。 可以将一个产品的内部表象与产品的生成过程分割开来 , 从而可以使一个建造过程生成具有不同的内部表象的产品( 将一个复杂对象的构建与它的表示分离, 使得同样的构建过程可以创建不同的表示 ). 这样用户只需指定需要建造的类型就可以得到具体产品, 而不需要了解具体的建造过程和细节 .
在建造者模式中, 角色分指导者 (Director) 与建造者 (Builder): 用户联系指导者 , 指导者指挥建造者 , 最后得到产品 . 建造者模式可以强制实行一种分步骤进行的建造过程.
SqlSessionFactoryBuilder充当的就是建造者角色 ,sqlSession就是我们最后得到的产品。
3.3 SqlSessionFactory
SqlSessionFactory 接口对象是一个重量级对象(系统开销大的对象),是 线程安全 的,所以一个应用只需要一个该对象。创建SqlSession 需 SqlSessionFactory 接口的 openSession() 方法。
默认的 openSession()方法没有参数,它会创建有如下特性的 SqlSession :
1 、会开启一个手动提交的事务(也就是不自动提交)。
2 、将从由当前环境配置的 DataSource 实例中获取 Connection 对象。事务隔离级别将会使用驱动或数据源的默认设置。
3 、预处理语句不会被复用,也不会批量处理更新。
openSession(true) :创建一个有自动提交功能的 SqlSession
openSession(false) :创建一个非自动提交功能的 SqlSession ,需手动提交
openSession() :同 openSession(false)
3.4 SqlSession
SqlSession 接口对象用于执行持久化操作(内存数据写入数据库)。一个 SqlSession 对应着一次数据库会话,一次会话以 SqlSession 对象的创建开始,以SqlSession 对象的关闭结束。
SqlSession 接口对象是 线程不安全 的,所以每次数据库会话结束前,需要马上调用其 close() 方法,将其关闭。再次需要会话,再次创建。 SqlSession 在方法内部创建,使用完毕后关闭。
SqlSession 类中有超过 20 个方法,我们常用的几乎都是执行语法相关的方法。
这些方法被用来执行定义在 SQL 映射的 XML 文件中的 SELECT 、 INSERT 、 UPDATE 和 DELETE 语句。它们都会自行解释,每一句都使用语句的 ID 属性和参数对象,参数可以是原生类型(自动装箱或包装类)、 JavaBean 、 POJO 或 Map 。

selectOne 和 selectList的不同仅仅是selectOne必须返回一个对象或null值。如果返回值多于一个,那么就会抛出异常。
selectMap 稍微特殊一点,因为它会将返回的对象的其中一个属性作为 key 值,将对象作为 value 值,从而将多结果集转为 Map 类型值。
3.5 Mybatis****架构/工作流程

1 、 Mybatis.xml 文件是 mybatis 框架的全局配置文件,配置了 mybatis 框架运行的环境等信息。
Mapper1.xml..... 是 SQL 的映射文件,文件中配置了所有的操作数据库的 sql 语句, 在mybatis全局配置文件中去加载这些sql映射文件 。
2 、 通过mybatis环境等配置信息构建SqlSessionFactroy , 相当于是产生连接池
3 、 由会话工厂创建SqlSession即会话 (连接),操作数据库需要通过 SqlSession 进行的。
4 、 Mybatis 底层自定义了 Executor执行器 的接口操作数据库, Executor 接口有两个实现,一个基本的执行器,一个是缓存的执行器。
5 、 Mapped statement 也是 mybatis 框架一个底层的封装对象,他包装了 mybatis 配置信息以及 sql 映射信息。 Mapper.xml文件中的一个SQL语句对应一个Mapped statement对象 , sql 的 id 就是 Mapped statement 的 id 。
6 、 Mapped statement 对 SQL 执行输入参数的定义,输入参数包括 HashMap 、基本类型、 pojo, Executor通过Mapped statemen在执行SQL语句前进行输入映射即将输入java对象映射到sql语句中,执行完毕SQL之后,输出映射就是JDBC编码中的对preparedStatement 执行结果的定义。
4、原有的Dao方式开发
4.1****创建sqlSession工具类

4.2创建TeamDao接口和实现类


测试:

sql映射文件Team.xml

结果

5.使用ThreadLocal优化sqlSession工具类
**5.0.**ThreadLocal的理解
ThreadLocal 并非是一个线程的本地实现版本,它并不是一个 Thread ,而是 threadlocalvariable( 线程局部变量 ) 。也许把它命名为 ThreadLocalVar更加合适。 线程局部变量 (ThreadLocal) 其实的功用非常简单,就是这个变量 为每一个使用该变量的线程都提供一个变量值的副本 , 是Java 中一种较为特殊的 线程绑定机制 ,是 每一个线程都可以独立地改变自己的副本,而不会和其它线程的副本冲突。 A线程改变,不会影响B线程 。
实例:

5.1.SqlSession线程不安全处理方案
保证多个线程使用的sqlSession是相互独立的,没有关联,若A、B使用同一个sqlSession,若A使用完close关闭sqlSession,那么B就无法执行了。可以给每一个线程绑定一个副本的sqlSession,这就需要使用ThreadLocal。
优化后的工具类

6**、使用Mapper的接口编写Mybatis项目**
6.1什么是Mapper****接口

在前面例子中自定义 Dao 接口实现类时发现一个问题: Dao 的实现类其实并没有干什么实质性的工作,它仅仅就是通过 SqlSession 的相关API 定位到映射文件 mapper 中相应 id 的 SQL 语句,真正对 DB 进行操作的工作其实是由框架通过 mapper 中的 SQL 完成的。
所以, MyBatis 框架就抛开了 Dao 的实现类,直接定位到映射文件 mapper 中的相应 SQL 语句,对DB 进行操作。这种对 Dao 的实现方式称为 Mapper接口 的动态代理方式。
就是我们不再需要编写dao接口的实现类,直接由mapper接口的动态代理,在程序运行的时候代理我们实现接口实现类,最终由mybatis操作db。
Mapper 动态代理方式无需程序员实现 Dao 接口。 接口是由 MyBatis 结合映射文件自动生成的动态代理实现的。
6.2****使用Mapper动态代理
注意,通过Mapper接口 的动态代理帮我们生成了接口实现类,接口的方法要与映射文件中的对应的id名称一致,否则无法定位到指定的sql。
6.2.1编写接口TeamMapper.java

创建TeamMapper.xml文件 , 与 Team.xml 内容几乎一样,只有 namespace="com.chen.mapper.TeamMapper" 修改为接口的完全限定名

在mybatis.xml配置文件中注册映射文件

6.2.2 getMapper****方法获取代理对象
只需调用SqlSession的getMapper()方法,即可获取指定接口的实现类对象。

6.3****实现原理
Mapper接口的动态代理是如何在程序运行期间帮我们创建接口的实现类对象的?
我们是通过SqlSession 的 getMapper()方法获取到了接口的实现类对象,该方法是基于jdk的动态代理在程序运行的时候代理我们创建接口对象,就是通过Proxy.newProxyInstance()方法进行的动态代理,第一参数传递类加载,第二个参数传递接口类集合,第三个参数回调程序编写代理规则,在这里代理生成接口实现类。


7**、增删改查中的细节**
7.1插入数据的时候返回自增的id值
即我们将一个对象插入数据库中时,是不提供主键id的值得,id自增自动赋值,那么现在希望插入数据后返回这条数据的id值?
7.1.1.返回Integer类型的自增id值
Team实体类

TeamMapper接口(只是用add)

TeamMapper.xml映射文件(只看add)

注册TeamMapper.xml映射文件到mybatis配置文件

测试


7.1.2.返回字符串类型的自增id值
添加一张新表:球队记录表
CREATE TABLE `gamerecord` (
`recordId` varchar(36) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`homeTeamId` int DEFAULT NULL COMMENT '主队ID',
`gameDate` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '比赛日期',
`score` int DEFAULT NULL COMMENT '得分',
`visitingTeamId` int DEFAULT NULL COMMENT '客队ID',
PRIMARY KEY (`recordId`) USING BTREE,
KEY `homeTeamId` (`homeTeamId`) USING BTREE,
KEY `visitingTeamId` (`visitingTeamId`) USING BTREE,
CONSTRAINT `gamerecord_ibfk_1` FOREIGN KEY (`homeTeamId`) REFERENCES `team` (`teamId`) ON DELETE RESTRICT ON UPDATE RESTRICT,
CONSTRAINT `gamerecord_ibfk_2` FOREIGN KEY (`visitingTeamId`) REFERENCES `team` (`teamId`) ON DELETE RESTRICT ON UPDATE RESTRICT
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC; 实体类:球队记录实体类
实体类:球队记录实体类

mapper接口GameRecordMapper

映射文件GameRecordMapper.xml,添加selectKey节点

测试


7.2 输入映射(传参到sql)
7.2.0.parameterType只能接收一个参数
接收的是基本类型(Integer/String..)的话是可以省略parameterType该属性、若是实体类对象,那么sql中占位符位置必须是实体类中属性。
**7.2.1.**使用下标方式/#{arg0}或/#{param1}

实体类还是Team
mapper接口还是TeamMapper,新添加方法

TeamMapper.xml配置文件中添加如下:

测试类添加方法:


7.2.2.通过**@Param****注解传递多个传参**
在方法形参前加 @Param(" 自定义参数名称 ") , mapper 文件中使用 /#{ 自定义参数名称 } 方式传参。
TeamMapper 接口添加如下内容:
TeamMapper.xml映射文件添加
测试


7.2.3.通过map来传递多个参数
Map 集合可以存储多个值,使用 Map 向 mapper 文件一次传入多个参数。 Map 集合使用 String 的 key , Object 类型的值存储参数。 mapper 文件使用 /# { key } 引用参数值
TeamMapper 接口添加如下内容:

TeamMapper.xml配置文件中添加如下
测试类添加方法:

 7.2.4. 通过pojo类传递多个参数
7.2.4. 通过pojo类传递多个参数
与map传递多个参数类似,要求映射文件中的参数占位符必须和pojo类中的属性完全一致。
自己封装的查询条件的类
TeamMapper接口添加如下内容:
TeamMapper.xml 配置文件中添加如下:
测试

总结:

**7.3 /#{}和${}的区别--**面试中喜欢出的考题
7.3.1 /#{}
/#{} : 表示一个占位符,通知Mybatis 使用实际的参数值代替。
并使用 PrepareStatement 对象执行 sql 语句 , /#{…} 代替 sql 语句的 “?” 。这个是 Mybatis 中的首选做法,安全迅速

7.3.2 ${}
${} : 表示字符串原样替换 ,通知 Mybatis 使用 $ 包含的 “ 字符串 ” 替换所在位置。
使用 Statement 或者 PreparedStatement 把 sql 语句和 ${} 的内容连接起来。 一般用在替换表名,
列名,不同列排序等操作 。
例如:根据球队名称,球队位置查询球队列表
方式 1 :sql中直接给出列名
teamMapper接口
teamMapper.xml

测试

方拾二:sql中使用${}代替列名,使用不同列作为查询条件
teamMapper接口

teamMapper.xml 测试
测试

7.4 输出映射resultType
resultType: 执行 sql 得到 ResultSet 转换的类型,使用类型的完全限定名或别名。如果返回的是集合,设置的是集合元素的类型,而不是集合本身。 resultType 和 resultMap, 不能同时使用 。
7.4.0.输出pojo类型
7.4.1.输出简单类型(单行单列)可省
如果查询sql返回的是简单类型且是单行单列(只要一个值)。resultType写值得类型或可以省略
案例:返回球队的总记录数
teamMapper接口
teamMapper.xml映射文件

测试

7.4.2.输出map集合类型(单行多列)
teamMapper接口

teamMapper.xml映射文件

测试


7.4.3.输出List集合类型(多行多列)
输出list集合类型--当返回多行多列时使用,list中元素是map,每个map描述一条记录

teamMapper接口

teamMapper.xml

测试


当我们只需要查询表中几列数据的时候可以将 sql 的查询结果作为 Map 的 key 和 value 。一般使用的是 Map<Object,Object>.。Map 作为接口返回值, sql 语句的查询结果最多只能有一条记录。大于一条记录会抛出 TooManyResultsException 异常。
如果有多行,使用 List<Map<Object,Object>>.
7.5. 输出映射resultMap
当使用resultType="com.chen.pojo.Team"返回Team对象时,mybatis会把sql查询结果自动映射到Team对象中,前提是Team属性与表的列名是一致的,那么当不一致时,这样写就会报错,这时就需要使用resultMap去自定义表和实体类的映射关系 。
我们可以使用resultMap 去编写表中的列与实体类中属性的映射。更灵活把列值赋值给指定属性。
常用在列名和 java 对象属性名不一样的情况。
使用方式:
1.先定义resultMap,指定列名和属性的对应关系
2.在<select>中把resultType替换为resultMap
teamMapper接口

teamMapper.xml映射文件

测试


7.6. 数据库表中列与实体类属性不一致的处理方式
准备工作:创建表:
CREATE TABLE `users` (
`user_id` int NOT NULL AUTO_INCREMENT COMMENT '用户id',
`user_name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL COMMENT '用户姓名',
`user_age` int DEFAULT NULL COMMENT '用户年龄',
PRIMARY KEY (`user_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ROW_FORMAT=DYNAMIC;

7.6.1.使用列别名和****resultType
数据库表中列与实体类属性不一致,且实体类属性不能修改情况下, 可以给列起别名,让列的别名和实体类属性一致,这样去映射 。
实体类 Users.java
接口 UsersMapper.java
映射文件 UsersMapper.xml
映射文件注册到mybatis配置文件
测试类 TestUsersMapper.java


7.6.2.使用****resultMap
见上面7.6.1
8**、Mybatis的全局配置文件**
使用的 mybatis.xml 就是 Mybatis 的全局配置文件。
全局配置文件需要在头部使用约束文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">8.1 全局配置文件配置的内容
MyBatis 配置文件包含了会影响 MyBatis 行为的设置和属性信息。 配置文档的顶层结构如下:
configuration (配置)
properties--属性:加载外部的配置文件,例如加载数据库的连接信息
Settings--全局配置参数:例如日志配置
typeAliases--类型别名
typeHandlers----类型处理器
objectFactory-----对象工厂
Plugins------插件:例如分页插件
Environments----环境集合属性对象
environment(环境变量)
transactionManager(事务管理器)
dataSource(数据源)
Mappers---映射器:注册映射文件用
8.2****属性(properties)
属性可以在外部进行配置,并可以进行动态替换 。我们既可以在 properties 元素的子元素中设置(例如 DataSource 节点中的 properties 节点),也可以在 Java 属性文件中配置这些属性。
数据源中有连接数据库的四个参数数据,我们一般都是放在专门的属性文件中, mybatis 的全局配置文件直接从属性文件中读取数据即可。
1 、在 resources 目录创建 jdbc.properties 文件,文件名称可以自定义。

jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://127.0.0.1:3306/team?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT
jdbc.username=root
jdbc.password=root2 、 mybatis 的全局配置文件引入属性文件
<properties resource = "jdbc.properties" />
3 、使用属性文件中的值
在 properties 元素的子元素中设置,这种写法注意url中&需要转义。
8.3设置settings
MyBatis 中极为重要的调整设置,它们会改变 MyBatis 的运行时行为 . 例如我们配置的日志就是应用之一。其余内容参考 设置文档
一个配置完整的 settings 元素的示例如下:
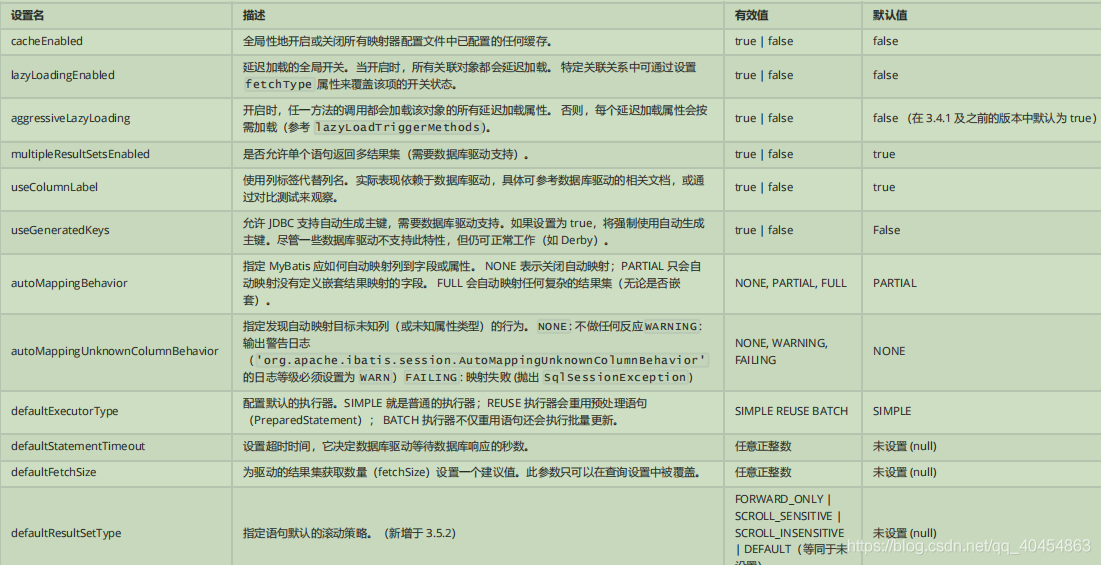
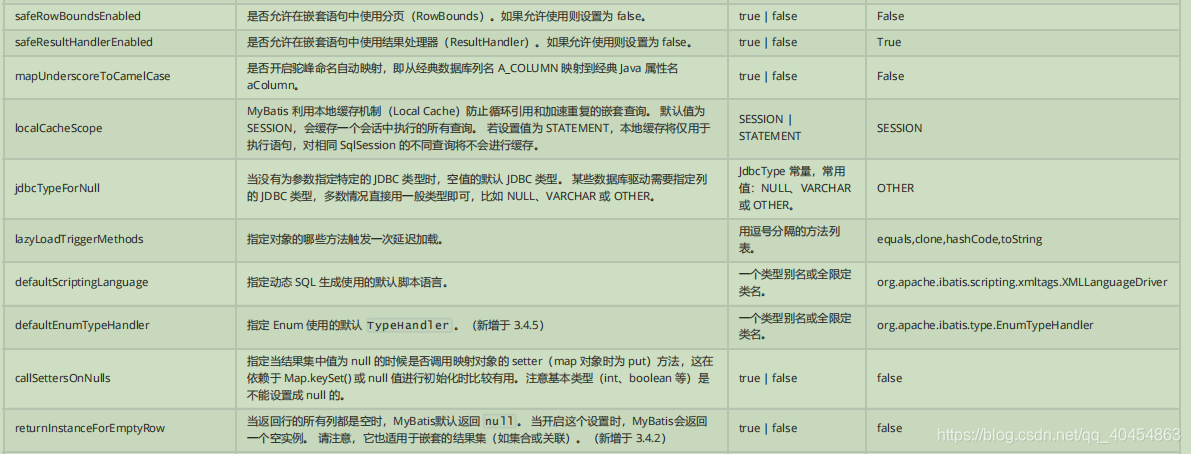

8.4类型别名typeAliases
类型别名可为 Java 类型设置缩写名字。 仅用于 XML 配置,意在降低冗余的全限定类名书写。
就是给xml中这些类的完全限定名起给简单的别名, 注意不要给namespace起别名

8.4.1 Mybatis****中已经支持/内置的别名
下面是一些为常见的 Java 类型内建的类型别名。它们都是不区分大小写的,注意,为了应对原始类型的命名重复,采取了特殊的命名风格。
8.4.1 Mybatis****中已经支持的别名
下面是一些为常见的 Java 类型内建的类型别名。它们都是不区分大小写的,注意,为了应对原始类型的命名重复,采取了特殊的命名风格。



8.4.2自定义别名
对于自定义的类,我们可以给其起个别名

在配置文件配置别名,注意查看<typeAliases>该放在哪个位置,通过
<configuration>进入查看配置顺序
可以直接使用别名替代全类名

8.5****映射器 Mappers(将映射文件映射到mybatis配置文件)
将映射文件映射到mybatis配置文件中。
配置有多种方式:
8.5.1**、 类路径引用映射文件**
语法: <mapper resource=""/>
使用相对于类路径的资源 , 从 classpath 路径查找文件
例如: <mapper resource="com/chen/mapper/TeamMapper.xml" />
**8.5.2、**使用的mapper接口的完全限定名
语法 :<mapper class=""/>
使用的 mapper 接口的完全限定名
要求:接口和映射文件同包同名
例如 <mapper class="com.kkb.mapper.GameRecordMapper"/>
8.5.3**、将包内的映射器接口实现全部注册为映射器****--**推荐
语法 :<package name=""/>
指定包下的所有Mapper接口
如: <package name="com.chen.mapper"/>
注意:此种方法要求 Mapper 接口名称和 mapper 映射文件名称相同,且在同一个目录中。

8.6 dataSource****标签
Mybatis 中访问数据库支持连接池技术,而且是采用的自己的连接池技术。在 Mybatis 的 mybatis.xml 配置文件中,通过来实现 Mybatis 中连接池的配置。 MyBatis 在初始化时,根据的 type 属性来创建相应类型的的数据源 DataSource 。
Mybatis 的数据源分为三类
UNPOOLED: 不使用连接池的数据源
POOLED: 使用连接池的数据源
JNDI :使用 JNDI 实现的数据源
前两个数据源都实现 javax.sql.DataSource 接口

8.7 Mybatis如何管理****事务
8.7.1**、默认是需要手动提交事务的**
Mybatis 框架是对 JDBC 的封装,所以 Mybatis 框架的事务控制方式,本身也是用 JDBC 的 Connection 对象的 commit(), rollback() .Connection 对象的 setAutoCommit() 方法来设置事务提交方式的。自动提交和手工提交。
<transactionManager type="JDBC"/> 在mybatis配置中使用该标签指定 MyBatis 所使用的事务管理器。
MyBatis 支持两种事务管理器类型 :jdbc ** ** 与 managed 。
JDBC :使用 JDBC 的事务管理机制,通过 Connection 对象的 commit() 方法提交,通过 rollback() 方法 回滚。默认情况下, mybatis 将自动提交功能关闭了,改为了手动提交,观察 日志可以看出,所以我们在程序中都需要自己提交事务或者回滚事务。

managed:由容器来管理事务的整个生命周期(如Spring容器)。
8.7.2**、自动提交事务**
SqlSessionFactory 的 openSession 方法重载,可以设置自动提交的方式。
如果 sqlSession = SqlSessionFactory.openSession(true); 参数设置为 true,再次执行增删改的时候就不需要执行sqlSession.commit()方法,事务会自动提交

9**、Mybatis中的关系映射**
就是如何给一个实体类中基本属性以及关联属性(对象/list集合)去映射查询的结果,通常是一对多关系的两表连接查询中遇到。
或者说对一/对多关系的结果映射的处理方式有哪些
表结构如图
附表的外键指向主表的主键

球队与球员关系:一对多关系
一个球队有多个球员
一个球员属于一个球队
在java中球员如何实现多对一的关系的绑定,在mybatis中又是如何进行对一关系的映射?
在java中球队如何实现一对多的关系的绑定,在mybatis中又是如何进行对多关系的映射?
连接查询的结果集(查询球员信息包含所在球队信息)在mybatis中是如何映射到实体类的?
9.1****对一关系映射的处理方式(三种方式)
**9.1.0.需求:**查询球员信息包含所在球队信息
9.1.1****实体类
添加关联字段Team球队对象

9.1.2 mapper****接口
9.1.3对一映射方式1**:通过关联对象打点调用属性的方式**
方式1:对一关系的映射:两表的连接查询+通过关联对象打点调用属性的方式
PlayerMapper接口

PlayerMapper.xml
baseResultMap映射

测试


9.1.4对一映射方式2**:直接引用关联对象的Mapper映射**
要求: 1 、两表的连接查询
2、关联对象中已经存在被引用的resultMap

PlayerMapper.xml 映射文件
resultMap所继承当前映射文件中的baseResultMap

resultMap所引用的TeamMapper映射文件中的baseResultMap

测试



9.1.5对一映射方式3**:直接引用关联对象的单独查询的方法**
要求:1、不需要两表的连接查询 ,拆开查询
2、关联对象中已经存在被引用的查询方法

同上,这里只展示映射文件添加的内容:

9.1.6****测试


9.2****对多关系的结果映射的两种处理方式
9.2.0.查询球队信息以及拥有的球员信息
Team球队实体类 添加关联字段List集合存储球队的球员

9.2.1方式1**:连接查询****+**引用关联对象的结果映射

TeamMapper接口添加方法

TeamMapper.xml映射文件

测试


9.2.2方式2**:不使用连接查询+引用关联对象的单独查询的方法**

先在PlayerMapper接口中定义根据teamId查询球员的方法

PlayerMapper.xml映射文件中

TeamMapper接口定义方法

TeamMapper.xml映射文件

测试

10、Mybatis****动态SQL
Mybatis使用标签构建动态SQL语句
动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接SQL语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL ,可以彻底摆脱这种痛苦。
使用动态 SQL 并非一件易事,但借助可用于任何 SQL 映射语句中的强大的动态 SQL 语言, MyBatis 显著地提升了这一特性的易用性。
咱们之前学习过 JSTL ,所以动态 SQL 元素会让你感觉似曾相识。在 MyBatis 之前的版本中,需要花时间了解大量的元素。借助功能强大的基于 OGNL 的表达式, MyBatis 3 替换了之前的大部分元素,大大精简了元素种类,现在要学习的元素种类比原来的一半还要少。
10.1 where标签构建动态SQL多条件查询
案例:球队的多条件查询
10.1.1.原有写法:根据不同条件拼接 SQL 语句

10.1.2.where标签构建动态SQL多条件查询
自己封装的查询条件类 QueryTeamVO.java :

TeamMapper.java 接口添加:

TeamMapper.xml映射文件添加:

测试


10.2 set****标签构建动态sql的更新update
10.2.1****原有的更新存在的弊端
当前台只是更新team中几个属性,会导致team其它属性数据丢失
TeamMapper接口

TeamMapper.xml映射文件

测试



10.2.2使用set标签构建动态的SQL语句
TeamMapper接口

TeamMapper.xml映射文件

测试


10.3 forEach****标签构建动态sql的批量添加/删除
10.3.1****批量添加
TeamMapper接口

TeamMapper.xml映射文件
测试



10.3.2****批量删除
TeamMapper接口

TeamMapper.xml映射文件

测试


11**、分页插件**
11.1 jar****依赖

11.2在Mybatis****全局配置文件中添加插件配置
mybatis中的配置都是有顺序要求的
11.3****使用插件



12**、Mybatis缓存**
12.1****缓存作用
缓存是一般的 ORM 框架都会提供的功能,目的就是 提升查询的效率和减少数据库的压力 。将经常查询的数据存在缓存(内存)中,用户查询该数据的时候不需要从磁盘(关系型数据库文件)上查询,而是 直接从缓存中查询,提高查询效率,解决高并发问题 。
MyBatis 也有一级缓存和二级缓存,并且预留了集成第三方缓存的接口/中间件,如果项目比较小,对缓存要求不高,可以使用一级二级缓存就足够了,对并发非常高的大型项目,一般选择第三方的缓存中间件
只有在查询的时候才会去缓存查找,增删改操作的还是数据库,并清空缓存。
12.2 一级缓存:SqlSession级别的缓存,自动开启
12.2.1****一级缓存工作原理
在操作数据库时需要构造 sqlSession 对象,在对象中有一个 ( 内存区域 ) 数据结构( HashMap )用于存储缓存数据。不同的 sqlSession 之间的缓存数据区域( HashMap )是互相不影响的。
一级缓存的 作用域 是同一个 SqlSession ,在同一个 sqlSession 中两次执行相同的 sql 语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率
当一个 sqlSession 结束后该 sqlSession 中的一级缓存也就不存在了。
Mybatis 默认开启一级缓存,存在内存中 ( 本地缓存 ) 不能被关闭,可以调用 clearCache() 来清空本地缓存,或者改变缓存的作用域。

当用户发起第一次查询 team=1001 的时候,先去缓存中查找是否有 team=1001 的对象;如果没有,继续向数据库中发送查询语句,查询成功之后会将 teamId=1001 的结果存入缓存中;
当用户发起第 2 次查询 team=1001 的时候,先去缓存中查找是否有 team=1001 的对象,因为第一次查询成功之后已经存储到缓存中,此时可以直接从缓存中获取到该数据,意味着不需要再去向数据库发送查询语句。
如果 SqlSession 执行了 commit( 有增删改的操作 ) ,此时该 SqlSession 对应的缓存区域被整个清空,目的避免脏读。
前提: SqlSession 未关闭。
12.2.2****清空缓存的方式
手动清空/执行增删改并提交后自动清空/关闭会话/xml中刷新缓存/提交回滚都会清空缓存
1、 session.clearCache( ) ;
2 、 execute update(增删改) ;
3 、 session.close( );
4 、 xml 配置 flushCache="true" ;
5 、 rollback ;
6 、 commit 。
12.3二级缓存:Mapper****级别的缓存
12.3.0.二级缓存工作原理
当多个SqlSession 去查询同一个 Mapper 的同一条 sql 语句(参数相同), 得到数据会存在二级缓存区域,多个 SqlSession 可以共用二级缓存,二级缓存是跨 SqlSession的。同样的当增删改并提交后缓存也会被清空。
二级缓存是多个 SqlSession 共享的,其 作用域 是 mapper 的同一个 namespace 。
不同的 sqlSession 两次执行相同 namespace 下的 sql 语句参数相同即最终执行相同的 sql 语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。
Mybatis 默认没有开启二级缓存,需要在 setting 全局参数中配置开启二级缓存。
如果缓存中有数据就不用从数据库中获取,大大提高系统性能。
如果两个session不是从同一个Factory获取,那么二级缓存将不起作用。
二级缓存原理图:
12.3.1****使用二级缓存步骤
1.在mybatis配置文件中开启二级缓存

2.在需要二级缓存的Mapper中添加缓存标记

3.实体类必须实现Serializable接口
因为缓存是需要写入数据的

4.测试二级缓存
如果两个session不是从同一个Factory获取,那么二级缓存将不起作用。

12.3.2****二级缓存的禁用
当在Mapper映射文件中使用了二级缓存,那么该映射文件中所有的select语句都会启用缓存,我们可以去禁用某个sql查询。
对于变化比较频繁的 SQL ,可以禁用二级缓存。
在开始了二级缓存的 XML 中对应的 statement 中设置 useCache=false 禁用当前 Select 语句的二级缓存,意味着该 SQL 语句每次只需都去查询数据库,不会查询缓存。
useCache 默认值是 true 。对于一些很重要的数据尽不放在二级缓存中。

12.3.3****缓存的属性配置
缓存中有哪些属性
1.映射语句文件中的所有select语句将会被缓存;
2.映射语句文件中的所有CUD操作将会刷新缓存;
3.缓存会默认使用LRU(Least Recently Used)算法来收回;
3.1、LRU – 最近最少使用的:移除最长时间不被使用的对象。
3.2、FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
3.3、SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
3.4、WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
4.缓存会根据指定的时间间隔来刷新(默认情况下没有刷新间隔,缓存仅仅调用语句时刷新);
5.缓存会存储列表集合或对象(无论查询方法返回什么),默认存储1024个对象。
6.缓存会被视为是read/write(可读/可写)的缓存,意味着检索对象不是共享的,而且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。


如果想在命名空间中共享相同的缓存配置和实例,可以使用cache-ref元素来引用另外一个缓存
<cache-refnamespace="com.kkb.mapper.TeamMapper"/>
// 引用 TeamMapper 命名空间中的 cache 。
13**、反向生成插件**
13.0.反向生成几个注意点
根据单表反向生成这些内容,包括单表的最基本的增删改查、还有接口、映射文件,包括动态查询,动态的插入更新,多条件查询都写好了,只要是单表操作,都给我们生成了,我们只需要引用方法就可以了,sql语句都写好的。
同一张表只能一次反向生成,除非删除掉之前生成的内容,不然再一次反向生成的内容会追加的,比如出现两个BaseResultMap。
如果其它数据库有相同的表,也会被反向生成的
13.1****插件的配置
在 pom.xml 文件中的中中添加如下插件配置

generatorConfig.xml 内容
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<!-- 配置生成器 -->
<!--注意:
1.同一张表只能一次反向生成,除非删除掉之前生成的内容,不然再一次反向生成的内容会追加的,比如出现两个BaseResultMap
2..如果其它数据库有相同的表,也会被反向生成的-->
<generatorConfiguration>
<!--1、数据库驱动jar:添加自己的jar路径 -->
<classPathEntry location="E:\mysql8.0驱动程序\mysql-connector-java-8.0.16.jar" />
<context id="MyBatis" targetRuntime="MyBatis3">
<!--去除注释 -->
<commentGenerator>
<property name="suppressAllComments" value="true" />
</commentGenerator>
<!--2、数据库连接 -->
<jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
connectionURL="jdbc:mysql://127.0.0.1:3306/team?useUnicode=true&characterEncoding=utf-8&
useSSL=false&serverTimezone=GMT" userId="root" password="64531515z">
</jdbcConnection>
<!-- 默认false,把JDBC decimal 和 numeric 类型解析为 Integer;
为 true时把JDBC decimal和numericC类型解析为java.math.BigDecimal -->
<javaTypeResolver>
<property name="forceBigDecimals" value="false" />
</javaTypeResolver>
<!--3、生成实体类 指定包名 以及生成的地址 (可以自定义地址,但是路径不存在不会自动创建 使用Maven生成在target目录下,会自动创建)-->
<javaModelGenerator targetPackage="org.bowei.pojo" targetProject="src\main\java">
<property name="trimStrings" value="true" />
</javaModelGenerator>
<!--4、生成SQLmapper.xml映射文件 -->
<sqlMapGenerator targetPackage="org.bowei.mapper" targetProject="src\main\resources"> </sqlMapGenerator>
<!--5、生成Dao(Mapper)接口文件,-->
<javaClientGenerator type="XMLMAPPER" targetPackage="org.bowei.mapper" targetProject="src\main\java"> </javaClientGenerator>
<!--6、要生成哪些表(更改tableName和domainObjectName就可以) -->
<!-- tableName:要生成的表名
enableCountByExample:Count语句中加入where条件查询,默认为true开启
enableUpdateByExample:Update语句中加入where条件查询,默认为true开启
enableDeleteByExample:Delete语句中加入where条件查询,默认为true开启
enableSelectByExample:Select多条语句中加入where条件查询,默认为true开启
selectByExampleQueryId:Select单个对象语句中加入where条件查询,默认为true开启 -->
<!--
<table tableName="Team"
enableCountByExample="false"
enableUpdateByExample="false"
enableUpdateByPrimaryKey="false"
enableDeleteByExample="false"
enableDeleteByPrimaryKey="false"
enableSelectByExample="false"
selectByExampleQueryId="false">
<property name="useActualColumnNames" value="true"/>
</table>
-->
<!--根据表反向生成这些内容,包括
单表的最基本的增删改查、还有接口、映射文件,包括动态查询,多条件查询都写好了,只要是单表操作,我们就不需要动,只需要选择要用的-->
<table tableName="Users">
<!--表不区分大小,比如表字段teamId,由表生成的实体类属性是teamid,下面设置就是针对这个问题-->
<property name="useActualColumnNames" value="true"/>
</table>
</context>
</generatorConfiguration>
我们只需要提供数据表,以及反向生成插件和配置即可。 


生成后检查映射文件中只有一个ResultMap就表示生成正常,没有同名的表被生成。可以看到生成的映射文件中你能想到的所有单表查询的sql都写好了,包括动态的更新、插入(即对象中属性不全都有值),多条件查询等,我们只需要引用id名即可。

13.2****使用反向生成中的多条件查询方法


版权说明 : 本文为转载文章, 版权归原作者所有 版权申明
原文链接 : https://blog.csdn.net/qq_40454863/article/details/119546556
内容来源于网络,如有侵权,请联系作者删除!
相关文章

热门标签
更多最新文章
更多- 浏览(1168) 发布于 2023-01-15
- 浏览(471) 发布于 2023-01-08
- 浏览(796) 发布于 2023-01-08
- 浏览(806) 发布于 2023-01-08
- 浏览(471) 发布于 2023-01-01
目录
- 1、Mybatis概述
- 2**、Mybatis入门案例**
- 3**、Mybatis对象分析**
- 4、原有的Dao方式开发
- 5.使用ThreadLocal优化sqlSession工具类
- 6**、使用Mapper的接口编写Mybatis项目**
- 7**、增删改查中的细节**
- 8**、Mybatis的全局配置文件**
- 9**、Mybatis中的关系映射**
- 10、Mybatis****动态SQL
- 11**、分页插件**
- 12**、Mybatis缓存**
- 13**、反向生成插件**